
Imagina un modelo de inteligencia artificial capaz de razonar con una precisión asombrosa, comparable a los mejores modelos actuales, y que no solo puede aprender por sí mismo, sino que también puede enseñar a otros modelos más pequeños. Esto es exactamente lo que propone DeepSeek-R1, un avance revolucionario en el aprendizaje por refuerzo. En este artículo, exploraremos cómo este modelo está redefiniendo las capacidades de razonamiento en la inteligencia artificial. ¡Acompáñanos para descubrir cómo está transformando el panorama de los modelos de lenguaje!
1. ¿Qué es DeepSeek-R1?
DeepSeek-R1 es el resultado de un enfoque innovador que utiliza aprendizaje por refuerzo a gran escala para potenciar las capacidades de razonamiento en modelos de lenguaje. Este modelo es una evolución de DeepSeek-R1-Zero, un modelo que se entrena sin datos supervisados, permitiendo que desarrolle habilidades de razonamiento únicamente a través de refuerzo positivo. DeepSeek-R1 refina esta base mediante datos iniciales (“cold start”) cuidadosamente diseñados y un proceso de entrenamiento en múltiples etapas.
2. Logros de DeepSeek-R1
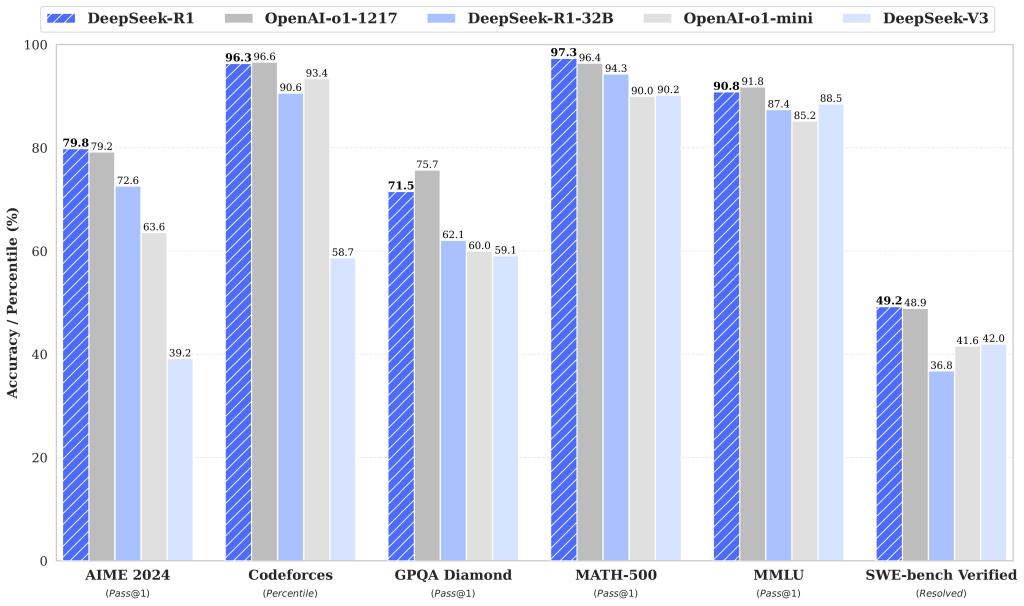
El rendimiento de DeepSeek-R1 es comparable al de modelos avanzados como OpenAI-o1-1217. En tareas de razonamiento matemático y codificación, alcanza una precisión de hasta el 97.3% en el benchmark MATH-500 y se sitúa en el percentil 96.3 en Codeforces, un entorno competitivo de programación. Además, en tareas de conocimiento general y educación, sobresale con puntuaciones destacadas en benchmarks como MMLU (90.8%) y GPQA Diamond (71.5%).
3. La magia del aprendizaje por refuerzo
DeepSeek-R1-Zero, precursor de este modelo, mostró un fenómeno fascinante: su capacidad de autoevolución. Durante el entrenamiento, el modelo no solo mejoró su precisión, sino que desarrolló espontáneamente estrategias avanzadas como reflexión y verificación de pasos intermedios, sin necesidad de programación explícita. Este proceso culminó en lo que los investigadores llaman un «momento aha», donde el modelo reevalúa problemas y encuentra soluciones más eficientes.
4. Destilación: Pequeños modelos, grandes capacidades
Uno de los aportes más innovadores de DeepSeek-R1 es la capacidad de transferir su conocimiento a modelos más pequeños a través de la destilación. Estos modelos «destilados» como DeepSeek-R1-Distill-Qwen-32B han demostrado superar a otros modelos de código abierto, ofreciendo una alternativa eficiente para tareas intensivas en razonamiento.
5. Aplicaciones y futuro del modelo
DeepSeek-R1 no solo es una herramienta poderosa para matemáticas y codificación, sino también para tareas complejas como escritura creativa, análisis de documentos extensos y respuesta a preguntas generales. Los próximos pasos incluyen mejorar su compatibilidad con múltiples idiomas, optimizar su sensibilidad al formato de las solicitudes y expandir su utilidad en ingeniería de software.
Conclusión:
DeepSeek-R1 es un hito en el desarrollo de modelos de lenguaje, demostrando que el aprendizaje por refuerzo puede impulsar el razonamiento autónomo y la transferencia de conocimiento a modelos más pequeños. Este avance no solo amplía el alcance de lo que los modelos de IA pueden lograr, sino que también abre la puerta a nuevas posibilidades en áreas como educación, programación y resolución de problemas complejos.
Para más Información : 👇




